
티스토리 뷰
TRAIN_DATASET = sorted([x for x in Path("/Users/kibeom/HAI/dataset/train").glob("*.csv")])
TRAIN_DATASET
[PosixPath('/Users/kibeom/HAI/dataset/train/train1.csv'),
PosixPath('/Users/kibeom/HAI/dataset/train/train2.csv'),
PosixPath('/Users/kibeom/HAI/dataset/train/train3.csv'),
PosixPath('/Users/kibeom/HAI/dataset/train/train4.csv'),
PosixPath('/Users/kibeom/HAI/dataset/train/train5.csv'),
PosixPath('/Users/kibeom/HAI/dataset/train/train6.csv')]sorted 함수는 정렬할 데이터를 리스트로 만들어 반환하는 함수이다.
정렬할 데이터는 Path내의 csv 파일이다. csv 파일은 glob 메소드를 이용해 조회했다.
glob 메소드는 조건에 맞는 파일명을 리스트 형식으로 반환한다.
이렇게 작성하면 반복문을 사용할 필요 없이 한줄로 디렉토리 내의 조건에 맞는 파일을 조회할 수 있다.
def dataframe_from_csv(target):
return pd.read_csv(target).rename(columns=lambda x:x.strip())
def dataframe_from_csvs(targets):
return pd.concat([dataframe_from_csv(x) for x in targets])다음은 csv 파일을 dataframe으로 바꾸는 함수이다.
첫번째 함수를 먼저보자.
read_csv 메소드로 target csv를 읽고, rename으로 column의 이름을 바꾼다.
lambda는 익명으로 함수를 만드는 방법으로 람다 표현식이라고 불린다.
strip()함수는 문자열의 앞 뒤 공백을 제거하는 함수인데, x에 대해서 공백을 제거하겠다는 의미이다.
이를 따로 함수로 만들지 않고 rename안에서 표현하고, 공백이 제거된 x를 리턴한다.
결국 공백이 있는 column은 람다 표현식을 적용해 공백이 없는 이름으로 rename된다.
return 값은 읽어온 target의 데이터프레임이다.
두번째 함수는 첫번째 함수를 이용해 데이터프레임을 합친다. 즉, train1.csv, train2.csv, ... 등을 하나의 데이터프레임으로 합친다.
간단하게 하나의 함수로 번거로움을 덜었다.
TRAIN_DF_RAW = dataframe_from_csvs(TRAIN_DATASET)
TRAIN_DF_RAW
앞서 선언한 함수를 사용해 train dataset을 하나의 데이터프레임으로 만든다.
TIMESTAMP_FILED = "timestamp"
ATTACK_FIELD = "Attack"
VALID_COLUMNS_IN_TRAIN_DATASET = TRAIN_DF_RAW.columns.drop([TIMESTAMP_FILED,ATTACK_FIELD])
VALID_COLUMNS_IN_TRAIN_DATASET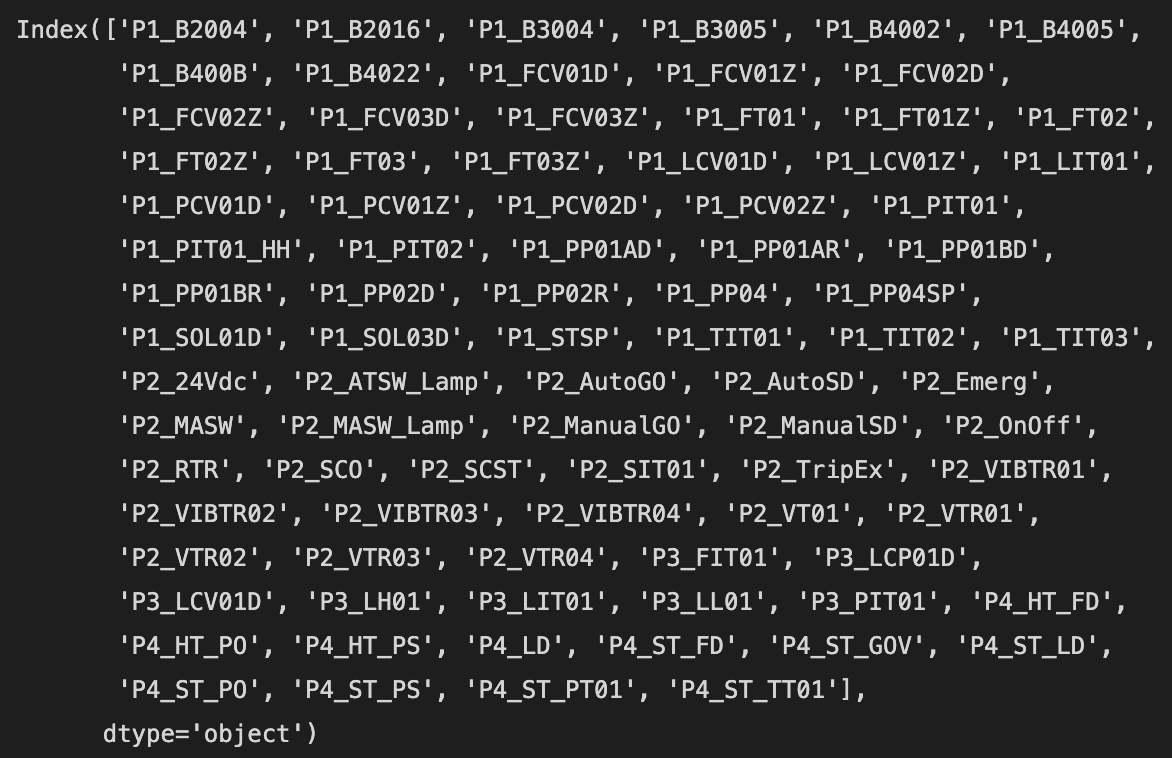
혹시나 존재하지 않는 필드가 존재하는 경우에 대비해 필드의 이름을 얻는다.
그리고 타임스탬프와 label 필드를 제외한다. 이 때 drop을 사용한다.
TRAIN_DF_RAW.drop(columns=["timestamp","Attack"])으로 사용해도 된다.
다음은 정규화 과정이다.
TAG_MIN = TRAIN_DF_RAW[VALID_COLUMNS_IN_TRAIN_DATASET].min()
TAG_MAX = TRAIN_DF_RAW[VALID_COLUMNS_IN_TRAIN_DATASET].max()
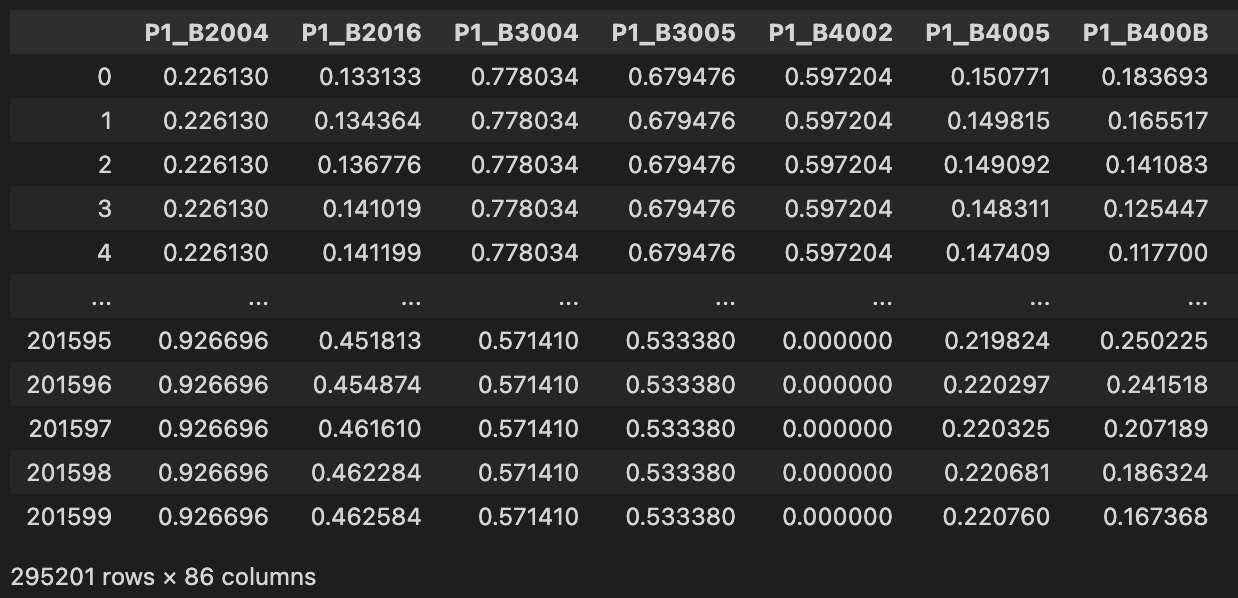
def normalize(df):
ndf = df.copy()
for c in df.columns:
ndf[c] = (df[c] - TAG_MIN[c]) / (TAG_MAX[c] - TAG_MIN[c])
return ndf정규화는 데이터 값들을 0~1 사이로 표현하는 방법이다.
def boundary_check(df):
x = np.array(df, dtype=np.float32)
return np.any(x > 1.0), np.any(x < 0), np.any(np.isnan(x))
boundary_check(TRAIN_DF)정규화를 했음에도 1보다 큰값이나 0보다 작은 값이다 nan 값이 있는지 확인한다.
'머신러닝' 카테고리의 다른 글
| 머신러닝 / PCA 이상탐지 (1) | 2023.05.17 |
|---|---|
| 머신러닝 / 공분산 행렬 PCA - 1 (1) | 2023.05.14 |
| 머신러닝 / 표준화, 정규화, 스케일링 (0) | 2023.01.16 |
| 머신러닝 / 차원 축소 1편 (0) | 2023.01.14 |
| 머신러닝 / 로지스틱 회귀 케라스 구현 (0) | 2023.01.13 |
- Total
- Today
- Yesterday
- many-to-one
- HTML
- porks
- SOME/IP
- 케라스
- many-to-many
- 크로스 엔트로피
- 로지스틱회귀
- AE
- 머신러닝
- AVTP
- SVM
- 이상탐지
- json2html
- AVB
- 딥러닝
- 회귀
- Ethernet
- 차량 네트워크
- one-to-many
- cuckoo
- automotive
- 차량용 이더넷
- Python
- 단순선형회귀
- automotive ethernet
- CAN-FD
- PCA
- 논문 잘 쓰는법
- problem statement
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |