
티스토리 뷰
출처 : https://repository.kihasa.re.kr/bitstream/201002/32608/1/%EA%B8%B0%EA%B3%84%ED%95%99%EC%8A%B5%28Machine%20Learning%29%20%EA%B8%B0%EB%B0%98%20%EC%9D%B4%EC%83%81%20%ED%83%90%EC%A7%80%28Anomaly%20Detection%29%20%EA%B8%B0%EB%B2%95%20%EC%97%B0%EA%B5%AC-%20%EB%B3%B4%EA%B1%B4%EC%82%AC%ED%9A%8C%20%EB%B6%84%EC%95%BC%EB%A5%BC%20%EC%A4%91%EC%8B%AC%EC%9C%BC%EB%A1%9C.pdf
1. 이상탐지 개념 및 특성
anomaly는 nomal의 반대되는 정상이 아니라는 의미이다.
분류는 두 범주를 구분할 수 있는 경계를 찾는 것이 목적이지만 이상 탐지는 다수의 범주를 고려하고 정상이 아닌 데이터의 범주들과 정상 데이터의 범주로 구분하는 것이 목적이다.
정상 범주 N1, N2 외에 o1,o2,O3이 이상 값들이다.

1.2. 이상탐지의 여러 요소
2.1 이상의 종류
2.1.1 점 이상(point anomaly)
위 그림과 같이 하나의 개체가 나머지에 대해 이상하다고 판단되는 경우이다.
2.1.2 맥락적 이상(contexual anomaly)
맥락 변수와 행동 변수에 대한 정의가 먼저 필요하다.
맥락 변수는 공간 자료의 위도나 경도, 시간 자료의 시간 등이다.
행동 변수는 맥락적이지 않은 특성이다. 강우량 자료에서 각 위치의 강우량 등이다.
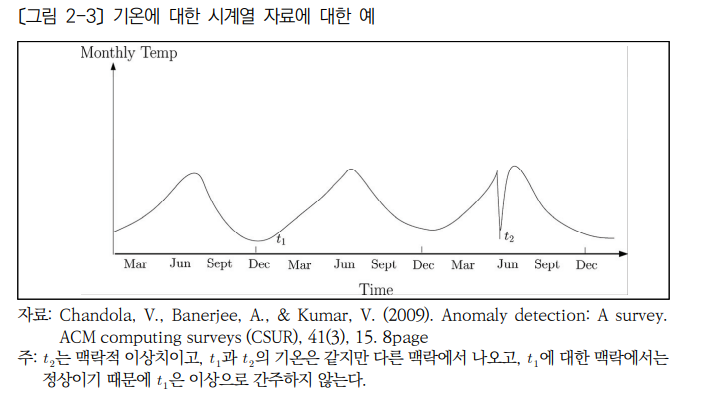
맥락적 이상은 특정한 맥락에서 행동 변수의 값으로 판단한다. 위 그림에서 t2시간이 맥락상 이상한 값이기 때문에 이상치로 탐지한다.
2. 이상 탐지 국내외 연구 사례
2.1 연구 분야별 탐지 기법 사례
2.1.1 침입 탐지
침입 탐지를 위해선 대용량의 자료를 다루기 위해 효율적인 계산이 필요하고, 오탐이 조금만 높아도 분석에 부담이 될 수 있다. 또한 실시간 분석이 핵심이다. 실시간 분석을 위해 비지도 기법이 선호된다.
2.1.2 사기 탐지
선형회귀분석, 군집분석 등 다변량 분석에서의 표준편차를 활용해 반복적으로 이상치를 측정해, 이상치로 볼 수 있는 특정 기준을 설정.
3. 이상 탐지 기법 연구
3.1 기계학습 기반 이상 탐지 기법
3.1.1 분류 기반 이상 탐지 기법
각 개체에 어느 클래스에 속하는지에 대한 라벨이 붙어 있는 자료로 분류기를 학습한 뒤,
학습된 모형으로 새로운 개체에 대해 각 클래스에 속할 확률을 예측.
정상 클래스와 나머지 클래스로 구분하도록 학습하고, 어느 클래스에도 속하지 않는 개체를 이상 값으로 처리한다.
가. 신경망 기반
신경망이 여러 정상 클래스를 학습한 후 테스트 자료를 그 신경망에 입력값으로 넣는 방식.
복제 신경망은 입력 자료를 저차원으로 압축하기 위해 제안된 신경망, 입력층과 출력층의 노드 수가 같고, 하나 이상의 은닉층으로 구성된 인코더를 통해 입력 자료를 압축하고, 디코더를 사용해 개체를 복원하여 출력값을 구한다.
나. 베이지안 네트워크 기반
테스트 개체의 각 정상 클래스와 이상에 대한 사후 확률을 추정해 가장 높은 확률에 해당하는 클래스로 지정한다.
각 클래스의 사전확률과 조건부확률은 학습 자료를 사용해 추정한다. 확률이 0이 나오는 경우 라플라스 스무딩으로 0 대신 적절한 양수값을 부여한다.
다. SVM 기반
학습 집합을 포함하는 영역을 학습한다. 영역 기반 학습 방법은 경계에만 초점을 맞추고 경계의 내,외부에서의 분포에는 관심을 갖지 않기 때문에, 분포에 둔감하고 자료의 샘플링이 어떻게 이루어졌는지와는 무관한 결과가 나온다.
라. 결정 규칙 기반
결정 규칙 기반 기법은 정상 자료를 판단하는 규칙들을 학습하고, 어떠한 규칙에도 해당하지 않는 개체를 이상으로 취급한다. 먼저 결정 규칙 학습 알고리즘을 활용해 규칙을 학습한다. 각 규칙에는 규칙이 올바르게 분류한 학습 개체의 개수와 전체 학습 자료 수의 비율에 비례하는 신뢰도 값이 부여된다. 그 다음 각 개체에 대해 해당 개체를 가장 잘 잡는 규칙을 찾고, 그 규칙의 신뢰도의 역수를 이상 점수로 한다.
분류 기반 이상 탐지 장단점
1. 여러 강력한 알고리즘 사용 가능
2. 이미 학습된 모형에 대해 예측만 하면 되므로 테스트 과정이 빠르다.
3. 다집단 분류에서 각 정상 개체 종류에 대한 라벨을 구하기 어려울 수 있다.
4. SVM 모델은 어떤 커널을 사용해야 할 지 결정해야 한다.
3.2 NN 기반 이상 탐지 기법
정상값들은 어떤 근방에 밀집되어 있고, 이상값은 각 근방에서 멀리 떨어져있다고 가정한다.
이 기법을 쓰려면 두 개체 사이 거리의 개념이 정의되어 있어야 한다. 연속형 변수는 유클리드 거리, 범주형 변수에서는 단순 일치 계수를 많이 쓴다.
NN 기법에서 이상 점수를 구하는 방법은 k번째로 가까운 개체의 거리를 이용하거나, 상대 밀도를 이용하는 방법이다.
3.2.1 k번째로 가까운 개체와의 거리 이용
이상 점수를 k번째로 가까운 개체와의 거리로 정의한다.
https://watchout31337.tistory.com/418
머신러닝/분류 - KNN 알고리즘
K - Nearest Neighbor KNN - 특정공간 내에서 K-NN은 새로 들어온 입력값이 어떤 그룹의 데이터와 가장 가까운가 분류하는 알고리즘 - k는 몇 번째로 가까운 데이터까지 살펴볼 것인가를 정함 - k의 default
watchout31337.tistory.com
3.2.2 상대 밀도 이용
각 개체 근방의 밀도를 추정. 근방의 밀도가 낮은 개체는 이상값이라 판단.
Local Outlier Factor(LOF)라는 이상 점수는 가장 가까운 k개 점들의 국소적 밀도의 평균과 자기 자신의 국소적 밀도의 비율로 정의된다. 정상값은 조밀한 영역에 위치해 국소적 밀도가 그 이웃들과 비슷한 반면, 이상값은 NN에 비해 상대적으로 국소적 밀도가 매우 낮기 때문에 큰 LOF 점수를 얻는다.
LOF는 core distance와 reachability distance 개념을 사용한다.
reachability distance는 다음 공식을 사용한다.

A의 local reachability density(lrd)값은 다음과 같다.

lrd(A)는 A에 속한 B의 reachability distance 평균의 역수값이다. 이 말은 A 개체가 밀도가 높은 곳에 있는 경우가 밀도가 낮은 곳에 있는 경우보다 lrd 값이 높다.

'머신러닝 > 딥러닝' 카테고리의 다른 글
| AI / Multi-modal에 관하여 (1) (0) | 2025.02.19 |
|---|---|
| Keras / RNN (Recurrent Neural Network) (0) | 2024.03.17 |
| MLP로 텍스트 분류 (0) | 2022.09.20 |
| 케라스 훑어보기 (1) | 2022.09.16 |
| 과적합을 막는 방법 (0) | 2022.09.16 |
- Total
- Today
- Yesterday
- 회귀
- SOME/IP
- AVB
- CAN-FD
- 차량 네트워크
- cuckoo
- 로지스틱회귀
- porks
- many-to-one
- PCA
- Ethernet
- 차량용 이더넷
- problem statement
- AVTP
- 단순선형회귀
- automotive
- AE
- HTML
- 논문 작성
- many-to-many
- 논문 잘 쓰는법
- automotive ethernet
- Python
- SVM
- 머신러닝
- one-to-many
- related work
- 케라스
- 딥러닝
- 이상탐지
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |