
티스토리 뷰
케라스는 손쉽게 딥 러닝을 구현할 수 있도록 도와주는 인터페이스다.
전처리
tokenizer() : 토큰화와 정수 인코딩을 위해 사용한다. 다음은 훈련 데이터로부터 단어 집합을 생성하고, 해당 단어 집합으로 임의의 문장을 정수 인코딩하는 과정을 보여준다.
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
tokenizer = Tokenizer() #단어의 토큰화와 정수 인코딩(단어에 정수를 부여)을 위한 토큰 생성
train_text = "the earth is an awesome place live" #훈련을 위한 단어 샘플
tokenizer.fit_on_texts([train_text]) #문자열 데이터를 빈도수 기준으로 단어 집합 생성
sub_text = "the earth is an great place live"
sequences = tokenizer.texts_to_sequences([sub_text])[0] #정수와 단어를 맵핑
print(tokenizer.word_counts.items()) #단어의 빈도 수를 나타내줌
print("정수 인코딩 : ",sequences)
print("단어 집합 : ",tokenizer.word_index)훈련 데이터에서 샘플의 길이는 서로 다를 수 있다. 이럴 때 모델의 입력으로 사용하려면 샘플의 길이를 동일하게 맞춰야 한다. 이런 작업을 패딩이라고 하는데 보통 숫자 0을 넣어서 맞춰준다. 사용하는 함수는 pad_sequence()를 사용한다. pad_sequence는 정해준 길이보다 긴 샘플은 자르고, 짧은 샘플엔 0으로 채운다.
pad_sequences([[1,2,3],[3,4,5,6],[7,8]],maxlen = 3, padding='pre')
#첫번째 인자 : 패딩을 진행할 데이터
#두번째 인자 : 데이터에 대해 정규화 할 길이
#세번째 인자 : pre는 패딩을 앞에, post는 패딩을 뒤에워드 임베딩
워드 임베딩이란 텍스트 내의 단어들을 밀집 벡터로 만드는 것이다. 원핫벡터와 차이점은 원핫벡터는 대부분 0의 값을 가지고, 하나의 1의 값을 가지는 벡터이고,단어 집합의 크기만큼 차원을 가지므로 차원이 크다. 또한 단어 벡터간의 유사도를 구할 수 없다.
워드 임베딩으로부터 얻은 임베딩 벡터는 상대적으로 저차원이며 모든 원소의 값이 실수이다.
Embedding : 임베딩은 단어를 밀집 벡터로 만드는 역할을 한다. 임베딩 층을 만드는 역할이다. 정수 인코딩이 된 단어들을 입력받아 임베딩 수행.
Sequential : 인공 신경망 모델에 층을 추가하기 위함.
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
model = Sequential()
model.add(...) # 층 추가
model.add(...) # 층 추가
model.add(...) # 층 추가#임베딩 층을 추가하는 예시
model = Sequential()
model.add(Embedding(vocab_size, output_dim, input_length))Embedding의 인자
첫번째 : 단어 집합의 크기, 총 단어의 개수
두번째 : 출력 차원. 결과로 나오는 임베딩 벡터의 크기
input_length : 입력 시퀀스의 길이
#전결합층을 추가하는 예시
model = Sequential()
model.add(Dense(1, input_dim=3, activation='relu'))Dense의 인자
첫번째 : 출력 뉴런의 수
두번째 : 입력 뉴런의 수
activation : 활성화 함수
위 예시에서 1개의 출력 뉴런을 가지며 3개의 입력 뉴런을 가지고 relu 함수를 활성화 함수로 전결합층을 만든다.
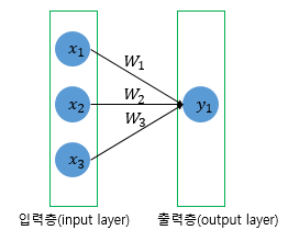
model = Sequential()
model.add(Dense(8, input_dim=4, activation='relu'))
model.add(Dense(1, activation='sigmoid')) # 출력층은닉층이 한개 있는 전결합층을 만들었다.
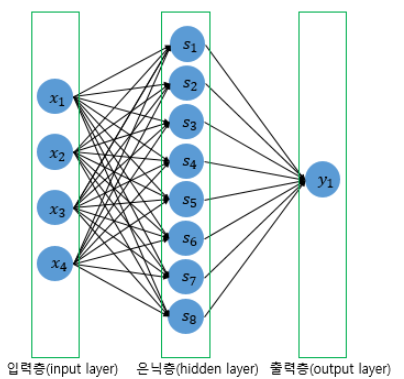
첫번째 Dense는 8개의 뉴런을 가지고 4개의 입력층을 가지며 relu를 활성화 함수로 사용하는 층이다.
두번째 Dense는 1개의 출력층을 가지고 sigmoid를 활성화 함수로 한다는 의미이다.
컴파일과 훈련
RNN을 이용해 이진 분류를 하는 전형적인 코드이다. 임베딩 층, 은닉층, 출력층을 설계한 후 컴파일을 한다.
compile() : 모델을 기계가 이해할 수 있도록 컴파일한다. 손실 함수와 옵티마이저, 메트릭 함수를 선택한다.
from tensorflow.keras.layers import SimpleRNN, Embedding, Dense
from tensorflow.keras.models import Sequential
voca_size = 10000
embedding_dim = 32
hidden_units = 32
model = Sequential()
model.add(Embedding(voca_size, embedding_dim))
model.add(SimpleRNN(hidden_units))
model.add(Dense(1, activation='sigmoid'))
model.compile(optimizer='rmsprop',loss='binary_crossentropy',metrics=['acc'])
model.fit(X_train,Y_train, epochs=10, batch_size=32)
model.evaluate(X_test, y_test, batch_size=32)
model.predict(X_input, batch_size=32)optimizer : 훈련 과정을 설정하는 옵티마이저를 설정.
loss : 훈련 과정에서 사용할 손실 함수를 설정.
metrics : 훈련을 모니터링하기 위한 지표를 선택.
fit() : 모델을 학습한다. 모델이 오차로부터 매개 변수를 업데이트 시키는 과정을 학습, 훈련, 또는 적합이라고 하는데 모델이 데이터에 적합해가는 과정이기 때문이다.
첫번째 인자 : 훈련 데이터
두번째 인자 : 지도 학습에서 레이블 데이터에 해당
epoch : 에포크, 기본값은 1
batch_size : 배치 크기, 기본값 32
이 외에도
vervbose : 0,1,2를 설정하는데 0은 아무것도 출력하지 않고 , 1은 훈련의 진행도를 진행막대로 출력, 2는 미니 배치마다 손실 정보를 출력해준다.
evaluate() : 테스트 데이터를 통해 학습한 모델에 대해 정확도 평가
첫번째 인자 : 테스트 데이터
두번째 인자 : 지도 학습에서 레이블 테스트 데이터
batch_size : 배치크기
predict() : 임의의 입력에 대한 모델의 출력값 확인
'머신러닝 > 딥러닝' 카테고리의 다른 글
| 머신러닝, 딥러닝 / 이상탐지(Anomaly Detection) (0) | 2023.03.13 |
|---|---|
| MLP로 텍스트 분류 (0) | 2022.09.20 |
| 과적합을 막는 방법 (0) | 2022.09.16 |
| 손실 함수, 옵티마이저, 에포크 (1) | 2022.09.15 |
| 행렬곱으로 이해하는 신경망 (0) | 2022.09.15 |
- Total
- Today
- Yesterday
- Python
- AVTP
- AVB
- Ethernet
- json2html
- 머신러닝
- 회귀
- 단순선형회귀
- SVM
- SOME/IP
- cuckoo
- problem statement
- 논문 잘 쓰는법
- 크로스 엔트로피
- 케라스
- HTML
- CAN-FD
- 차량용 이더넷
- 로지스틱회귀
- PCA
- 차량 네트워크
- one-to-many
- 딥러닝
- 이상탐지
- many-to-many
- many-to-one
- AE
- automotive ethernet
- automotive
- porks
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |