
티스토리 뷰
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
import numpy as np
fish = pd.read_csv('https://bit.ly/fish_csv_data')
fish.head()
print(pd.unique(fish['Species'])) #species 열만 출력
#데이터 준비
fish_input = fish[['Weight', 'Length', 'Diagonal', 'Height', 'Width']].to_numpy() #원하는 열을 리스트로 나열하여 선택, 괄호를 두개 사용해 이차원 배열로 생성
print(fish_input[:5])
fish_target = fish['Species'].to_numpy()
#훈련 세트, 테스트 세트 준비
train_input, test_input, train_target, test_target = train_test_split(fish_input,fish_target, random_state=42)
#표준화 처리
ss = StandardScaler()
ss.fit(train_input)
train_scaled = ss.transform(train_input)
test_scaled = ss.transform(test_input)
#이웃 분류기
kn = KNeighborsClassifier(n_neighbors = 3)
kn.fit(train_scaled, train_target)
print(kn.score(train_scaled, train_target))
print(kn.score(test_scaled, test_target))
print(kn.classes_) #타깃값 출력, 자동으로 알파벳 순서대로 나열됨
print(kn.predict(test_scaled[:5])) #5개의 test 샘플 예측한 결과
#클래스(타깃값)별로 확률값을 반환하는 proba로 샘플의 확률값 확인하기
proba = kn.predict_proba(test_scaled[:5]) #알파벳 순서대로 타겟에 대응하는 확률값 표시
print(np.round(proba, decimals=4)) #소수점을 반올림하는 round함수와 소수점 자리를 정하는 decimal 사용
#가장 가까운 이웃 확인
distances, indexes = kn.kneighbors(test_scaled[3:4])
print(train_target[indexes])
#로지스틱 회귀, 시그모이드 함수를 이용해 아주 큰 음수일 때 0이 되고, 아주 큰 양수일 때 1이 되도록함.(사실은 분류)
import matplotlib.pyplot as plt
z = np.arange(-5,5,0.1) #-5 ~ 5 사이에서 0.1 간격으로 배열 z를 만든다.
phi = 1/(1 + np.exp(-z)) #시그모이드 함수식 계산
plt.plot(z,phi)
plt.xlabel('z')
plt.ylabel('phi')
plt.show()#간단한 이진 분류 해보기
#0.5보다 크면 양성, 0.5보다 작으면 음성
char_arr = np.array(['A','B','C','D','E'])
print(char_arr[[True, False, True, False, False]]) #참인 경우에만 출력#훈련 세트에서 타겟 예측하기
from sklearn.linear_model import LogisticRegression
from scipy.special import expit
bream_smelt_indexes = (train_target == 'Bream') | (train_target == "Smelt") #bream인 경우와 smelt인 경우를 골라냄. bream이나 smelt 경우 True, 아닌 경우엔 False를 리턴함.
train_bream_smelt = train_scaled[bream_smelt_indexes]
target_bream_smelt = train_target[bream_smelt_indexes]
lr = LogisticRegression()
lr.fit(train_bream_smelt, target_bream_smelt)
print(lr.predict(train_bream_smelt[:5]))
print(lr.predict_proba(train_bream_smelt[:5])) #첫번째 열이 음성에 대한 확률, 두번째 열이 양성에 대한 확률
print(lr.classes_) #smelt가 양성
print(lr.coef_,lr.intercept_) #[[-0.4037798 -0.57620209 -0.66280298 -1.01290277 -0.73168947]] [-2.16155132], 각 값 * 각 샘플 값(무게, 길이 등) + intercept = z
decisions = lr.decision_function(train_bream_smelt[:5]) #5개의 z 값을 구함
print(decisions) #이 값을 시그모이드 함수로 계산해 확률을 얻음.
print(expit(decisions)) #시그모이드 함수 계산, [0.00240145 0.97264817 0.00513928 0.01415798 0.00232731], proba의 두번째 열과 동일 -> 양성 클래스에 대한 z값을 반환#다중 분류
#매개변수 C로 규제를 제어. alpha와 반대로 값이 작을수록 규제가 커짐.
from scipy.special import softmax
lr = LogisticRegression(C=20, max_iter=1000)
lr.fit(train_scaled, train_target)
print(lr.score(train_scaled, train_target))
print(lr.score(test_scaled, test_target))
print(lr.predict(test_scaled[:5])) #Test 샘플 5개의 예측값 출력
proba = lr.predict_proba(test_scaled[:5]) #Test 샘플 5개에 대해 클래스에 대한 확률 확인, 7개의 생선에 대해서의 확률, 소프트맥스함수를 사용해 확률 계산
print(lr.classes_)
print(np.round(proba,decimals=3)) #
print(lr.coef_.shape, lr.intercept_.shape)
#sofTmax에서 사용할 Z1~Z7의 값 확인
decision = lr.decision_function(test_scaled[:5])
print(np.round(decision, decimals = 2))
#Softmax 함수 사용해 확률 계산
proba = softmax(decision,axis = 1) #axis를 1로 지정해 각 행(각 샘플)에 대해 소트맥스를 계산, 지정하지 않으면 배열 전체에 대해 소프트맥스를 계산
print(np.round(proba, decimals = 3))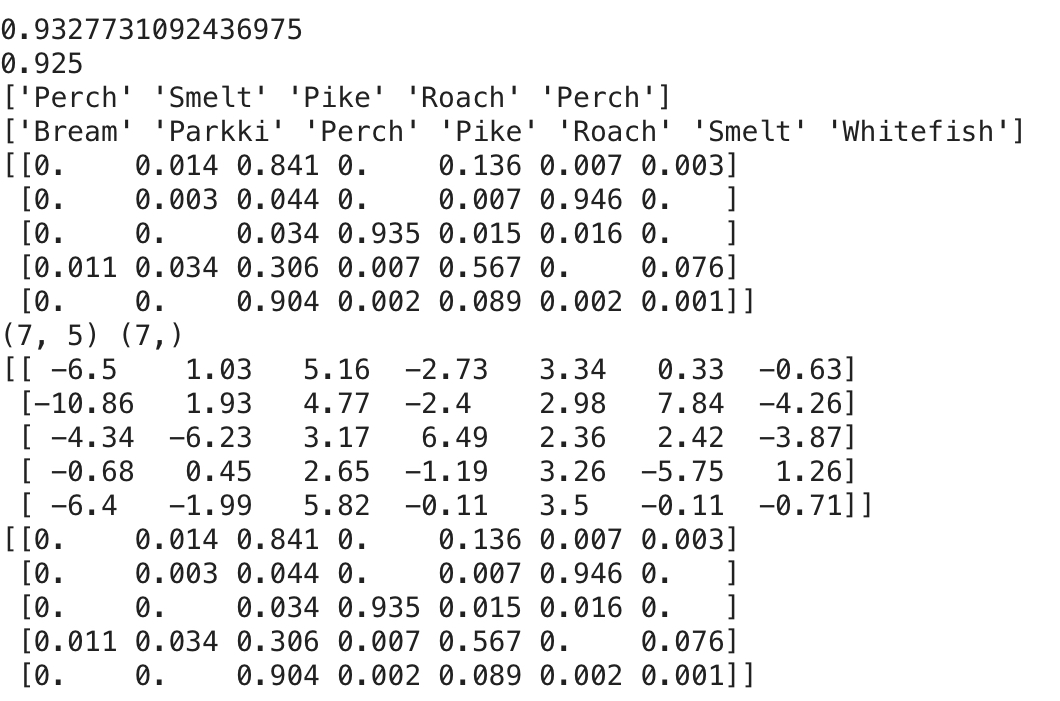
'머신러닝 > 혼자공부하는머신러닝' 카테고리의 다른 글
| 머신러닝 / kmeans 알고리즘 k 구하기 (0) | 2023.03.29 |
|---|---|
| 확률적 경사 하강법 (0) | 2022.09.06 |
| pandas csv read, 다중 선형 회귀 (0) | 2022.08.23 |
| 혼공머_3 (0) | 2022.08.23 |
| 혼공머_2 (0) | 2022.08.19 |
공지사항
최근에 올라온 글
최근에 달린 댓글
- Total
- Today
- Yesterday
링크
TAG
- porks
- 크로스 엔트로피
- problem statement
- Python
- AE
- 차량 네트워크
- 딥러닝
- 회귀
- 케라스
- cuckoo
- one-to-many
- 로지스틱회귀
- CAN-FD
- PCA
- 단순선형회귀
- automotive
- Ethernet
- many-to-one
- automotive ethernet
- json2html
- many-to-many
- SOME/IP
- AVTP
- HTML
- 논문 잘 쓰는법
- 차량용 이더넷
- 머신러닝
- 이상탐지
- SVM
- AVB
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
글 보관함